2015年12月,计科杀手 csslayer 创建了fcitx/fcitx5代码库,独自开始了对 Fcitx5 的开发。
如今五年过去了,Fcitx5 也日渐成熟。(个人感觉算法上相当不错
今年年初,我从 fcitx-rime 换到 fcitx5-rime ,感觉并不明显 (毕竟对于 Rime 用户来说从4到5最大的变化是界面
然后,在 Arch Linux CN 众多群友的诱惑下, 我决定尝试一下 Fcitx5 自带的拼音输入法。
首次使用的体验是相当的棒的,Fcitx5 在默认配置下表现良好,云拼音也有百度,Google,Google CN 三种可选尽管我不怎么用云拼音,整句输入也是相当的棒,还有输入预测功能。
但这并不是让我抛弃我在 Rime 积攒下的词库投靠老K输入法Fcitx5自带拼音的理由……真正的原因是最近发生的几件事……
- 首先是非常好的反馈体验,开发者老K对待用户非常友好,而且生产力十足
- 然后是 Felix 爬了维基百科制作了肥猫百万大词库,随后大佬 outloudvi 制作了萌娘百科词库,Fcitx5 的日用词库基本满足(AUR 上皆有打包,且在 Arch CN 源有打包
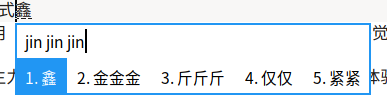
- 肥猫大词库中的一个讨论促使Fcitx5引入了一项新功能——根据前缀生成候选项,效果如图:
 这个功能我觉得对于长词输入是很棒的
这个功能我觉得对于长词输入是很棒的 - 添加了类似搜狗U模式的拆字模式,效果如图:
- 还有一件事是 Fcitx5 可以使用
fcitx,fcitx5,ibus的输入法模块(感觉黑科技 - 我从 rime 移植过来一份符号表,这样输入就方便了很多
正文
在经历了一天的过渡之后,我的主力输入法从 Rime 迁移到了 Fcitx5, 到目前为止体验良好
优势
- 上述几条个人认为皆为优势
fcitx5-rime支持加载动态库形式的 Rime 插件,在设置中填写插件名称即可使用,注意 octagram 插件名称与文件名并不一样(fcitx-rime无此支持,ibus-rime有此支持但是似乎配置文件有点问题(喜讯:Arch 官方仓库中的librime已经打包了 lua 和 octagram(即语料库)插件- 自带一套 $\LaTeX$ 简易输入表(虽然只能输入一小部分特殊字符
- 笔画过滤: 参见 Fcitx5_使用笔画过滤
- 以词定字
- 查看选中文字的 Unicode 编码:选中文字,然后使用快捷键 ctrl + alt + shift + u 可以查看选中文字的编码
- 更好的支持(Fcitx4 已经停止支持
关于安装
Arch
开发者老K有一篇 官方博文 可供参考,此外 Arch Linux CN 提供了 Git 版本的打包,虽然 Fcitx5 还没有发布正式版,但是Arch的[community]源已经提供了打包
可 sudo pacman -S fcitx5-im fcitx5-chinese-addons 直接安装,另外 CN 源有词库可用 sudo pacman -S fcitx5-pinyin-{zhwiki,moegirl}
Ubuntu
李先生有一篇 如何现在就在 Ubuntu 20.04 用上 Fcitx 5
hosxy 大佬提供了一个 PPA,将 Debian Sid 的 Fcitx5 port 到 Ubuntu 20.04 (Ubuntu 官方源中的 Fcitx5 是较旧版本,而 Fcitx5 最近几个月活跃开发并更新,很多东西都跟不上时代了 ( 与此相关的是一个 bug fix 修正了一个拼音:聒噪(guo zao)仅记录了古音“聒(gua)”,此外,Ubuntu 20.04 打包的版本未打包配置工具。
来自一个朋友的安装配置方法(不能保证一定可行):
用Ubuntu官方源安装fcitx5
sudo apt install fcitx5 fcitx5-pinyin fcitx5-chinese-addons fcitx5-frontend-gtk2 fcitx5-frontend-gtk3 fcitx5-frontend-qt5
然后再添加ppa安装kde-config-fcitx5
sudo add-apt-repository ppa:hosxy/test
sudo apt update
然后千万不要升级任何软件包
若要尝试自行编译,请参考 Debian 官方包打包脚本
PS1:Ubuntu 官方只为20.04及以后的版本提供了包
PS2: 若尝试在 Ubuntu 18.04 编译,请注意依赖问题,另外最新版 kcm-fcitx5 依赖 Qt 5.14+ 版本
Debian && Kali && etc.
参考 Ubuntu
Gentoo
Gentoo-zh Overlay 有提供打包
AOSC OS
其官方有提供打包
openSUSE
M17N 源有打包,但是似乎遇上了 已修复json-c 的依赖问题,等待维护者更新中
Manjaro && other distributions based on Arch
Manjaro Dev. 应该已经把肥猫的包偷过去了吧(
Parabola 有包,看签名应该 x86_64 的包是从 Arch 拿过去的
NixOS
已提交请求,位于 NixOS/nixpkgs#102626
Fedora and etc.
目前似乎无人打包,
已经有打包者在尝试打包了1,
现在 Copr 有包了 yanqiyu/fcitx5,
目前已在 Fedora 32 testing 有包2,
目前已在 Fedora 32 stable 有包,
打包者写有一篇介绍博客 如何下周就在 Fedora 32 用上 Fcitx 5(这文章名颇有 Fcitx5 博客一贯风格,还有一篇 如何更加优雅的在 fedora 上安装 fcitx5
自行编译请注意依赖问题
Flatpak
有 Flatpak 版本啦,参见 如何现在就用上 Fcitx 5 (Flatpak)
关于设置
推荐以下设置:
- 预测看个人喜好
- 启用颜文字
- 云拼音根据需要来,但是不推荐 Google 后端,原因显然
- preedit 也就是单行显示自己选择
- 安装肥猫百万大词库(墙裂推荐
- Lua 插件!!!自带日期和时间,另外推荐几个,内含进制转换、简易计算器和密码生成器
主题美化
有以下几种选择:
kimpanel(KDE)/gnome-shell-extension-kimpanel(Gnome) (同时这也应该是目前 Wayland 下唯一的方案)- Material Color 主题,有多种颜色以及单行双行两种模式,Arch 官方源有打包

- 黑色透明主题

- 黑色主题

- Materia EXP 主题,系统使用暗色主题的用户请谨慎使用

- Simple Blue 主题
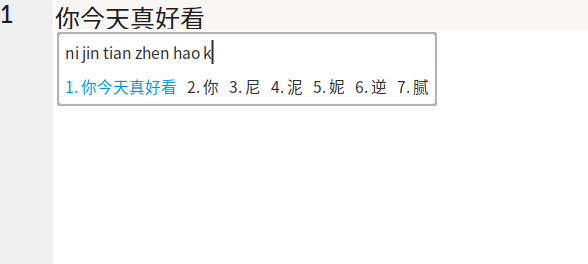
- Adwaita-dark,推荐 Gnome 用户使用
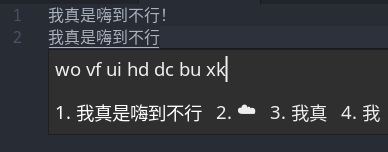
- 经典的Material 主题,这个主题同时支持4和5
我都没注意这个主题更新了 fcitx5 支持(fcitx5 版本有人在 AUR 上打了包,包名:fcitx5-skin-material - base16 material darker 主题
- 自制主题
(顺便写份主题文档吧
以上主题在 AUR 皆有打包(似乎目前已有主题在 AUR 上都有打包了
关于配置工具
开发者明确表示不会考虑开发基于 GTK 的图形配置工具,但在 fcitx5-configtool 中可以同时编译出 KCM 版本和纯 Qt 版本的配置工具(至于会不会依赖 KDE 就看你的发行版拆不拆包了(Arch 的做法是 KDE 相关依赖作为可选依赖,因此其他桌面环境用户安装 fcitx5-configtool 并不会引入 KDE
PS1: 老K终于想起来把那个极易引起误解的 repo 名改掉了
PS2: Ubuntu 20.04 打包的版本未打包配置工具。(不知道他们怎么想的)
关于从 Fcitx4 迁移
最新版本的 fcitx5-configtool 已经添加了迁移工具3,可执行文件名为 fcitx5-migrator,GUI 工具。
目前支持 pinyin, skk, rime, kkc, table(码表输入)和全局设置的迁移。
关于 Rime 用户
Fcitx5 相比 Fcitx4 增加了对于动态库形式(即 .so)的 librime 插件支持,几乎是你使用 librime 插件的唯一途径(Arch 官方的 librime 已经打包了 lua 和 octagram 插件
FAQ
-
在5月25日之前的 fcitx5 的主题代码中存在 bug fcitx/fcitx5#65,如果主题中直接使用了 RGB 颜色代码,那么显示时颜色会出现问题,表现出类似反色的效果。 该问题在5月25日修复4; 如果是 Material Color 主题 用户,可 checkout 至 hosxy/Fcitx5-Material-Color#commit=e57e56 或更新 fcitx5 使用。5
-
在10月2日之前的 Fcitx5 中,词库不会预先加载,而是会在第一次切换到对应输入法时加载,这使得使用较大词库时最初几秒不可用,此问题在10月2日修复6, 现在 Fcitx5 会在启动时预先加载默认的输入法的词库。
倡议
现在的问题是没有(很少有)其他发行版用户尝试 Fcitx5 来找出在其他发行版上的问题…… Arch 上的虫已经捉的差不多了……其他发行版上体验的改进需要你们的参与……
先写到这里,有需要再补充
Change log
- 2020-05-27 15:17 Edit: 增加几个皮肤
- 2020-06-13 18:27 Edit: 添加拆字模式介绍
- 2020-07-05 01:17 Edit: 增加几个皮肤,补充 PPA,添加倡议,补充说明一些编译相关问题,添加配置工具说明,补充一些发行版的安装方法
- 2020-07-05 11:28 Edit: 补充部分特性
- 2020-07-14 04:10 Edit: 更新部分包的状态,添加 Rime 相关问题
- 2020-08-07 11:04 Edit: 更新
kcm-fcitx5到fcitx5-configtool的包名变更,添加词库安装方案(Arch) - 2020-08-12 18:17 Edit: 更新 Fedora 打包状态
- 2020-08-16 12:37 Edit: 更新 Fedora 打包状态(Copr),更新 openSUSE 打包状态(M17N),补充关于 Ubuntu 20.04 中配置工具问题的解释,添加符号表
- 2020-08-16 14:20 Edit: 添加来自一个朋友的安装配置方法(Ubuntu)
- 2020-08-16 19:59 Edit: 更新一个与主题显示有关的 bug
- 2020-08-31 00:46 Edit: 更新 Fedora 打包状态(Fedora 32 testing)
- 2020-09-08 00:46 Edit: 更新 Fedora 打包状态(Fedora 32 stable)
- 2020-09-12 12:45 Edit: 添加迁移工具(fcitx5-configtool/fcitx5-migrator)
- 2020-09-29 11:57 Edit: 更新 openSUSE 打包状态(M17N)
- 2020-10-04 15:58 Edit: 更新关于词典预加载的问题
- 2020-11-04 15:04 Edit: Fcitx5 发 5.0 正式版啦
- 2020-11-06 21:37 Edit: 添加 NixOS 打包状态,更新 Fedora 打包状态
- 2020-11-29 00:01 Edit: 添加 Flatpak 打包状态
]]>